あらゆるウェブサイトから数秒でデータを抽出
あらゆるウェブページからワンクリックでデータを抽出。AIが商品、求人、リスティング、テーブルを自動検出します。ページネーション、無限スクロール、詳細ページに対応。CSV、XLSX、JSON、またはGoogle スプレッドシートに書き出せます。コーディング不要、アカウント不要、制限なし — 完全無料。
具体的な中身。
「メリットのごった煮」ではなく、具体的な動作です。ある機能が使えると私たちが言ったなら、30秒で試して、嘘なら嘘だと証明できます。
AIによる自動検出
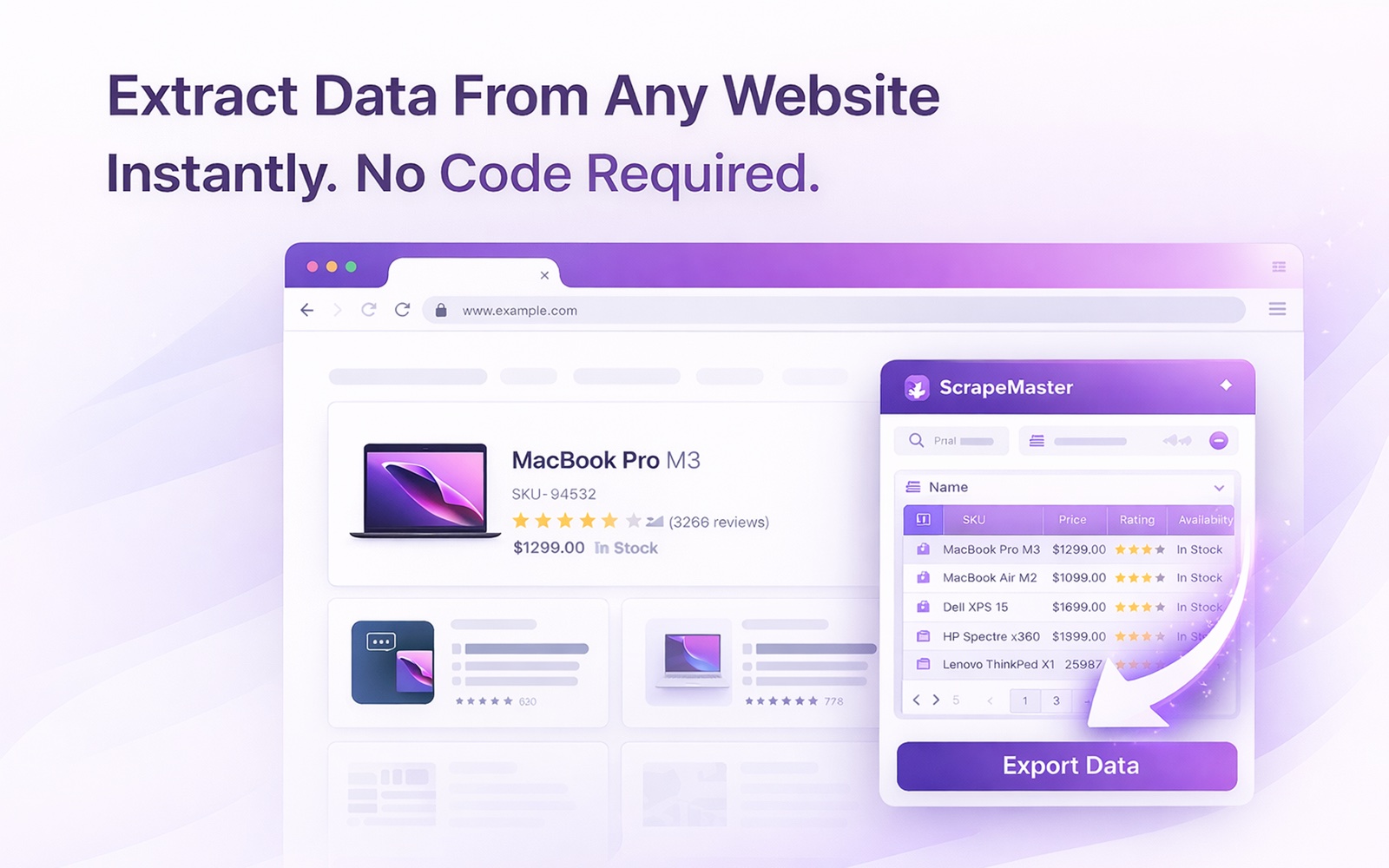
一度クリックするだけで、ScrapeMasterがページを解析し、繰り返し現れるデータのパターンを検出し、列名を賢く付けます — 設定も、セレクタも、コーディングも不要。
完全なスクレイピングパイプライン
次ページボタン、もっと読み込むボタン、番号付きページネーション、無限スクロールに対応し、さらに詳細ページへのリンクをたどってより深いデータまで取得します。
どこへでも書き出し
CSV、XLSX、JSONとしてダウンロード。あるいはクリップボードに直接コピーして、Google スプレッドシート、Excel、CRMへ即座に貼り付けられます。
3ステップ、10秒以内。
アイコンをクリック
ScrapeMasterがサイドパネルで開き、2〜4秒でデータを自動検出します。編集可能なテーブルが即座に表示されます。
カスタマイズして拡張
列の名前を変えたり、不要な列を削除したり。ページネーションを有効にしたり、項目のリンクをたどって複数ページにまたがってスクレイピングできます。
データを書き出す
抽出をクリックすると、進捗をリアルタイムで表示しながら全レコードを取得。その後、CSV、XLSX、JSONとしてダウンロードするか、Google スプレッドシート用にコピーします。
これを本当に必要としている人たち。
営業・マーケティング
競合の価格、商品リスティング、リード一覧、レビューデータを抽出し、分析やアプローチに活用します。
採用担当・人事
求人サイトから候補者リスト(氏名、役職、企業、連絡先)を集め、そのままATSに書き出します。
研究者・アナリスト
不動産リスティング、学術論文、行政記録、ニュースアーカイブなど、あらゆる公開情報源から構造化データを収集します。
インストール前によく聞かれること。
「できません」と言う部分も含めて、正直な回答を。ここで疑問が解決しない場合は、こちらまでメールしてください: [email protected].
ScrapeMasterは本当に無料ですか?
はい。有料プランも、行数制限も、クレジットカードも不要。マシンが保持できる限り、いくらでもデータを抽出できます。
ウェブスクレイピングは合法ですか?
公開されているデータのスクレイピングは、たいていの法域で一般に合法です。ただし、著作権のあるコンテンツの再公開、サイトの利用規約違反、GDPR/CCPAの対象となる個人データのスクレイピングといった特定のケースでは、法的な問題が生じることがあります。ScrapeMasterは中立的なツールであり、どう使うかはあなたの責任です。法的な状況を掘り下げたブログ記事もいくつか用意しています(LinkedIn、GDPR、CCPA、EU AI法)。
CSSセレクタやコーディングの知識は必要ですか?
いいえ。ScrapeMasterはほとんどのページで、2〜4秒以内に繰り返しのパターンを自動検出します。セレクタを1つも書くことなく、列の名前を変えたり、不要な列を削除したり、詳細ページへのリンクをたどったりできます。
JavaScriptを多用するサイト(React、Vue、Angular)でも動作しますか?
はい。拡張機能はブラウザ内で動くため、JavaScriptがレンダリングされたあとのページ — つまりあなたが見ているのとまったく同じもの — を見ています。SPA、無限スクローラー、動的なReactコンポーネントも、すべて対象になります。
ページネーションや無限スクロールに対応できますか?
はい。ScrapeMasterは次ページボタン、もっと読み込むボタン、番号付きページネーション、無限スクロールのパターンを自動検出します。抽出はページごとに進み、進捗はサイドパネルにリアルタイムで表示されます。
詳細ページへのリンクをたどって、そこからも抽出できますか?
はい。「詳細をたどる」機能は、各項目のリンクをバックグラウンドのタブで開き、あなたが定義した追加フィールドを抽出して、メインの結果テーブルに統合します。
サイトからブロックされてしまいませんか?
ScrapeMasterは通常のブラウザセッションを使い、リクエストを自然なペースで行います。それでも、ボット対策の厳しいサイト(LinkedIn、Cloudflareで保護されたサイト)で大量または高速に抽出すると、ブロックが発生することがあります。必要に応じて抽出の遅延を設定し、速度を抑えられます。この拡張機能はプロキシやフィンガープリントのローテーションは行いません。
対応している書き出し形式は?
CSV、XLSX(Excel互換)、JSON、そしてGoogle スプレッドシート、Excel、任意のCRMに貼り付けるための直接クリップボード。書き出したものは、ローカルのダウンロードフォルダに保存されます。
抽出したデータはブラウザの外に出ますか?
いいえ。抽出したレコードはIndexedDBにローカルで保存されます。唯一のネットワークリクエストは自動検出時で、そのときページのHTML構造(内容ではありません)が、セレクタを提案するために私たちの解析APIに送られます。抽出したデータそのものが、アップロードされることは決してありません。
ペイウォールやログインの壁を突破できますか?
いいえ。ScrapeMasterは、あなたがすでにブラウザで見られるページからデータを抽出します。ペイウォールを突破したり、ログイン要件を回避したり、CAPTCHAを解いたりはしません。ログインした状態で見られるものなら、ScrapeMasterは抽出できます。
抽出の設定を保存して、あとで再利用できますか?
はい。ScrapeMasterは列の構成、ページネーションのルール、詳細たどりの設定を、ドメインごとに保存します。あとで同じサイトを訪れると、保存された設定が自動で再適用されます。
どのブラウザで動作しますか?
Chrome、Edge、Brave、Arc、その他あらゆるChromium系ブラウザ。この拡張機能はChromeのサイドパネルAPIを使っており、これはFirefoxやSafariでは利用できません。