Извлекайте данные с любого сайта за секунды
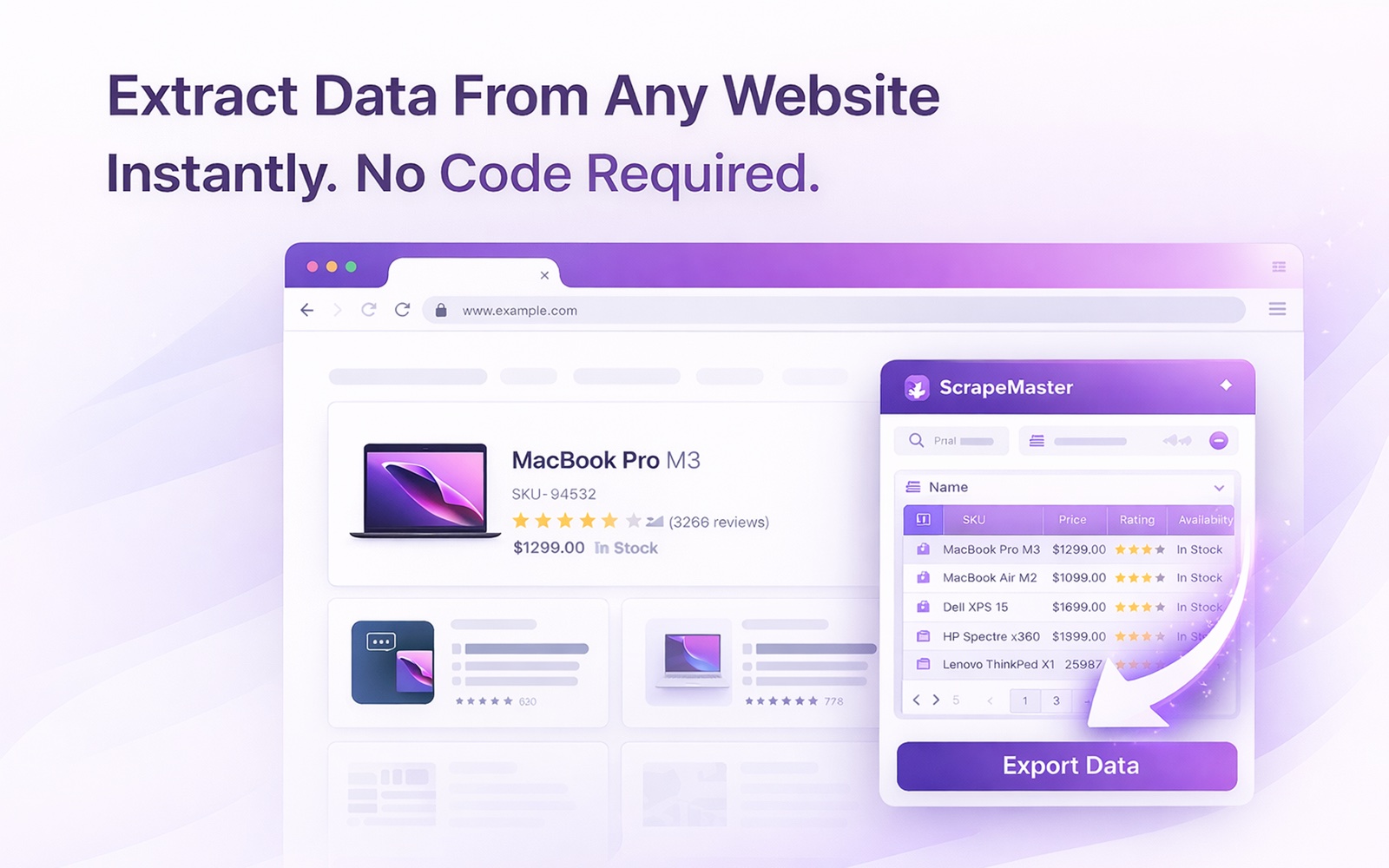
Извлечение данных с любой веб-страницы одним кликом. ИИ автоматически распознаёт товары, вакансии, объявления и таблицы. Справляется с пагинацией, бесконечной прокруткой и страницами с подробностями. Экспорт в CSV, XLSX, JSON или Google Sheets. Без программирования, без аккаунтов, без ограничений — полностью бесплатно.
Конкретика.
Реальное поведение, а не суп из абстрактных «преимуществ». Если мы говорим, что функция работает, вы можете проверить это за 30 секунд и доказать, что мы неправы.
Автораспознавание на основе ИИ
Нажмите один раз, и ScrapeMaster анализирует страницу, находит повторяющиеся шаблоны данных и разумно называет столбцы — без настройки, без селекторов, без кода.
Полный конвейер скрапинга
Справляется с кнопками «Следующая страница» и «Загрузить ещё», нумерованной пагинацией, бесконечной прокруткой и даже переходит по ссылкам на страницы с подробностями, чтобы собрать более глубокие данные.
Экспорт куда угодно
Скачивайте в CSV, XLSX или JSON. Или копируйте прямо в буфер обмена для мгновенной вставки в Google Sheets, Excel или вашу CRM.
Три шага, меньше десяти секунд.
Нажмите на иконку
ScrapeMaster открывается в боковой панели и автоматически распознаёт данные за 2–4 секунды. Тут же появляется редактируемая таблица.
Настройте и расширьте
Переименуйте столбцы, уберите лишние. Включите пагинацию или переход по ссылкам, чтобы скрапить сразу несколько страниц.
Экспортируйте данные
Нажмите «Извлечь», чтобы вытянуть все записи с отображением прогресса, затем скачайте в CSV, XLSX, JSON или скопируйте для Google Sheets.
Тем, кому это действительно нужно.
Продажи и маркетинг
Извлекайте цены конкурентов, списки товаров, каталоги лидов и данные отзывов для анализа и работы с клиентами.
Рекрутеры и HR
Собирайте списки кандидатов с job-бордов — имена, должности, компании, контакты — с экспортом прямо в вашу ATS.
Исследователи и аналитики
Собирайте структурированные данные из любого публичного источника — объявления о недвижимости, научные статьи, госреестры, новостные архивы.
О чём спрашивают перед установкой.
Честные ответы — в том числе там, где мы говорим «нет». Если здесь нет ответа на ваш вопрос, напишите на [email protected].
ScrapeMaster правда бесплатный?
Да. Никакого платного тарифа, ограничений по строкам, банковской карты. Вы можете извлечь столько данных, сколько поместится в вашу машину.
Легален ли веб-скрапинг?
Скрапинг общедоступных данных, как правило, законен в большинстве юрисдикций, но конкретные сценарии — повторная публикация контента, защищённого авторским правом, нарушение условий использования сайта, скрапинг персональных данных, подпадающих под GDPR / CCPA — могут создавать юридические риски. ScrapeMaster — нейтральный инструмент; как вы его используете, ваша ответственность. У нас есть несколько статей в блоге, где юридическая сторона разобрана глубже (LinkedIn, GDPR, CCPA, Закон ЕС об ИИ).
Нужно ли мне знать CSS-селекторы или программирование?
Нет. ScrapeMaster автоматически распознаёт повторяющиеся шаблоны на большинстве страниц за 2–4 секунды. Вы можете переименовывать столбцы, убирать лишние и переходить по ссылкам на страницы с подробностями, не написав ни одного селектора.
Работает ли он на сайтах с большим количеством JavaScript (React, Vue, Angular)?
Да. Поскольку расширение работает прямо в вашем браузере, оно видит страницу уже после отрисовки JavaScript — ровно так же, как вы. SPA, бесконечная прокрутка и динамические React-компоненты — всё это ему по зубам.
Справляется ли он с пагинацией и бесконечной прокруткой?
Да. ScrapeMaster автоматически распознаёт кнопки «Следующая страница» и «Загрузить ещё», нумерованную пагинацию и шаблоны бесконечной прокрутки. Извлечение идёт страница за страницей с отображением прогресса в боковой панели.
Может ли он переходить по ссылкам на страницы с подробностями и извлекать данные и оттуда?
Да. Функция «Переход к подробностям» открывает ссылку каждого элемента в фоновой вкладке, извлекает заданные вами дополнительные поля и вливает их обратно в основную таблицу результатов.
Не заблокируют ли меня из-за него на сайтах?
ScrapeMaster использует вашу обычную сессию браузера и делает запросы в естественном темпе. Тяжёлое или очень быстрое извлечение на сайтах с агрессивной анти-бот защитой (LinkedIn, сайты под Cloudflare) всё равно может вызвать блокировку; при необходимости можно настроить задержки между запросами. Расширение не ротирует прокси и цифровые отпечатки.
Какие форматы экспорта поддерживаются?
CSV, XLSX (совместимый с Excel), JSON и прямое копирование в буфер для вставки в Google Sheets, Excel или любую CRM. Экспортированные файлы сохраняются локально в папку загрузок.
Покидают ли извлечённые данные браузер?
Нет. Извлечённые записи хранятся локально в IndexedDB. Единственный сетевой запрос происходит во время автораспознавания, когда HTML-структура страницы (не её содержимое) отправляется в наш аналитический API, чтобы предложить селекторы. Сами извлечённые данные никогда не загружаются.
Может ли он обходить платные или логин-стены?
Нет. ScrapeMaster извлекает данные со страниц, которые вы уже видите в браузере. Он не обходит платные стены, не преодолевает требование входа и не решает CAPTCHA. Если вы видите это, войдя в аккаунт, — ScrapeMaster это извлечёт.
Можно ли сохранить настройки извлечения и переиспользовать их позже?
Да. ScrapeMaster сохраняет вашу настройку столбцов, правила пагинации и конфигурацию перехода к подробностям для каждого домена. При повторном визите на тот же сайт сохранённая конфигурация применяется автоматически.
В каких браузерах он работает?
Chrome, Edge, Brave, Arc и любой браузер на Chromium. Расширение использует Chrome Side Panel API, которого нет в Firefox и Safari.
Установите ScrapeMaster.
Бесплатно навсегда. Без аккаунта. Два клика. Удалить ещё в два, если не помогло.
Добавить в Chrome →