Wyodrębniaj dane z dowolnej strony w kilka sekund
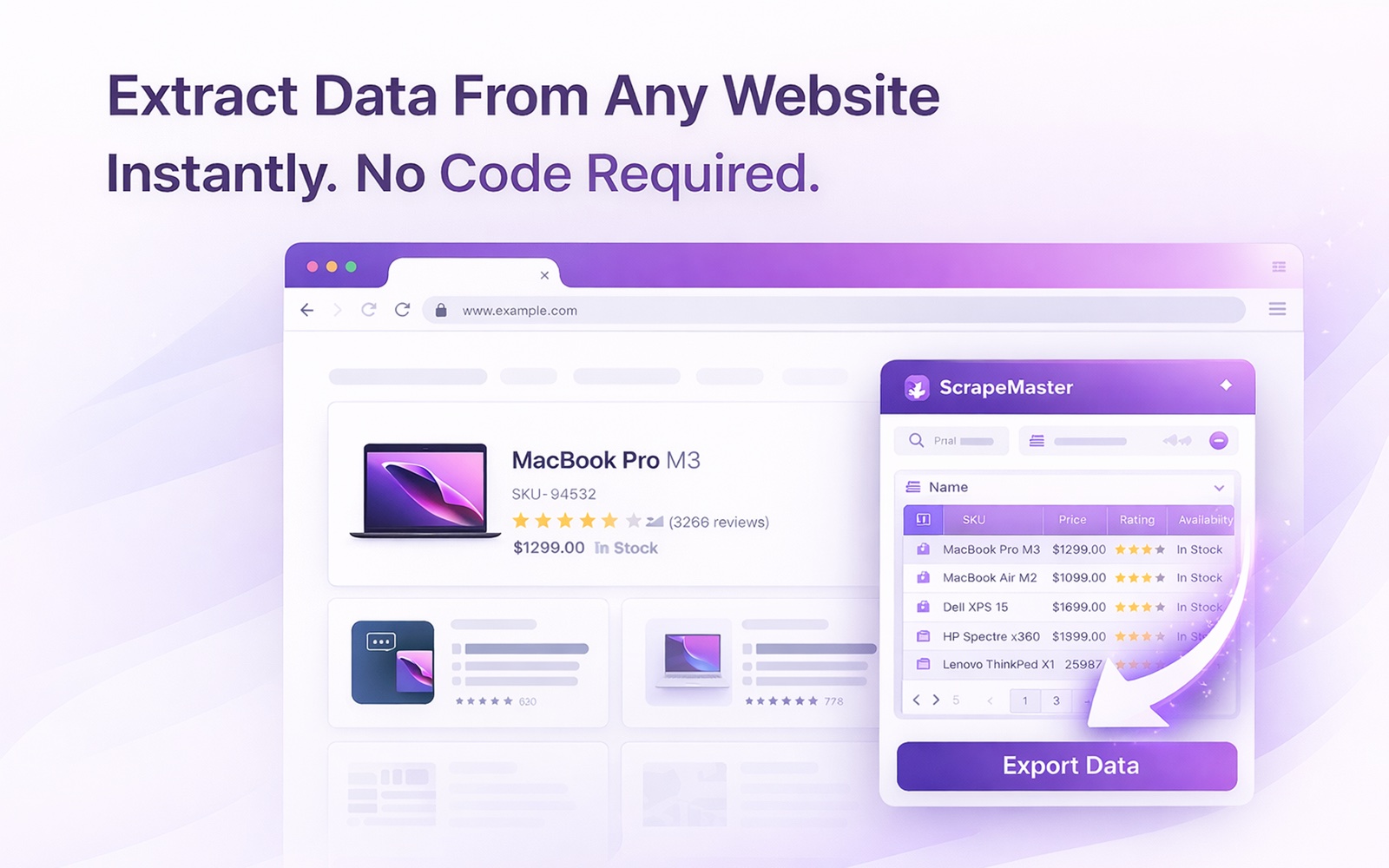
Wyodrębnianie danych z dowolnej strony jednym kliknięciem. AI automatycznie wykrywa produkty, oferty pracy, ogłoszenia i tabele. Radzi sobie z paginacją, nieskończonym przewijaniem i stronami szczegółów. Eksportuj do CSV, XLSX, JSON lub Arkuszy Google. Bez kodowania, bez kont, bez limitów — całkowicie za darmo.
Konkrety.
Konkretne działanie, a nie zupa z pustych obietnic. Jeśli mówimy, że funkcja działa, sprawdzisz to w 30 sekund i wykażesz nam, że się mylimy.
Automatyczne wykrywanie oparte na AI
Kliknij raz, a ScrapeMaster analizuje stronę, wykrywa powtarzające się wzorce danych i inteligentnie nazywa kolumny — bez konfiguracji, bez selektorów, bez kodowania.
Kompletny proces scrapowania
Obsługuje przyciski następnej strony, przyciski „wczytaj więcej”, paginację numerowaną, nieskończone przewijanie, a nawet podąża za linkami do stron szczegółów po głębsze dane.
Eksport dokądkolwiek
Pobierz jako CSV, XLSX lub JSON. Albo skopiuj bezpośrednio do schowka, by od razu wkleić do Arkuszy Google, Excela czy swojego CRM-a.
Trzy kroki, poniżej dziesięciu sekund.
Kliknij ikonę
ScrapeMaster otwiera się w panelu bocznym i automatycznie wykrywa dane w 2–4 sekundy. Edytowalna tabela pojawia się natychmiast.
Dostosuj i rozszerz
Zmień nazwy kolumn, usuń niepotrzebne. Włącz paginację lub podążaj za linkami elementów, by scrapować przez wiele stron.
Wyeksportuj swoje dane
Kliknij Wyodrębnij, aby pobrać wszystkie rekordy z widocznym na żywo postępem, a potem pobierz jako CSV, XLSX, JSON lub skopiuj do Arkuszy Google.
Ludzi, którym to naprawdę potrzebne.
Sprzedaż i marketing
Wyodrębniaj ceny konkurencji, oferty produktów, katalogi potencjalnych klientów i dane z recenzji do analizy i kontaktu.
Rekruterzy i HR
Zbieraj listy kandydatów z portali z ofertami pracy — nazwiska, stanowiska, firmy, dane kontaktowe — eksportowane prosto do twojego systemu ATS.
Badacze i analitycy
Zbieraj ustrukturyzowane dane z dowolnego publicznego źródła — ogłoszeń o nieruchomościach, prac naukowych, rejestrów urzędowych, archiwów prasowych.
Rzeczy, o które ludzie pytają przed instalacją.
Szczere odpowiedzi — łącznie z tym, gdzie mówimy „nie”. Jeśli czegoś tu nie znajdziesz, napisz na [email protected].
Czy ScrapeMaster jest naprawdę darmowy?
Tak. Bez wersji płatnej, bez limitów wierszy, bez karty płatniczej. Możesz wyodrębnić tyle danych, ile pomieści twój komputer.
Czy web scraping jest legalny?
Scrapowanie publicznie dostępnych danych jest w większości jurysdykcji zasadniczo legalne, ale konkretne przypadki — ponowne publikowanie treści objętych prawem autorskim, naruszanie regulaminu strony, scrapowanie danych osobowych podlegających RODO / CCPA — mogą rodzić problemy prawne. ScrapeMaster to neutralne narzędzie; to, jak go użyjesz, jest twoją odpowiedzialnością. Mamy kilka wpisów na blogu, które sięgają głębiej w krajobraz prawny (LinkedIn, RODO, CCPA, unijny akt o AI).
Czy muszę znać selektory CSS lub programowanie?
Nie. ScrapeMaster automatycznie wykrywa powtarzające się wzorce na większości stron w 2–4 sekundy. Możesz zmieniać nazwy kolumn, usuwać niepotrzebne i podążać za linkami do stron szczegółów bez pisania choćby jednego selektora.
Czy działa na stronach mocno opartych na JavaScript (React, Vue, Angular)?
Tak. Ponieważ rozszerzenie działa wewnątrz twojej przeglądarki, widzi stronę po wyrenderowaniu JavaScriptu — dokładnie tak jak ty. Aplikacje jednostronicowe (SPA), nieskończone przewijanie i dynamiczne komponenty Reacta — wszystko jest w zasięgu.
Czy radzi sobie z paginacją i nieskończonym przewijaniem?
Tak. ScrapeMaster automatycznie wykrywa przyciski następnej strony, przyciski „wczytaj więcej”, paginację numerowaną i wzorce nieskończonego przewijania. Wyodrębnianie przebiega strona po stronie, z postępem pokazywanym na żywo w panelu bocznym.
Czy potrafi podążać za linkami do stron szczegółów i wyodrębniać także z nich?
Tak. Funkcja „Podążaj za szczegółami” otwiera link każdego elementu w karcie w tle, wyodrębnia zdefiniowane przez ciebie dodatkowe pola i scala je z powrotem do głównej tabeli wyników.
Czy naraża mnie na zablokowanie przez strony?
ScrapeMaster korzysta z twojej normalnej sesji przeglądarki i naturalnie rozkłada żądania w czasie. Intensywne lub szybkie wyodrębnianie na stronach z agresywną ochroną przed botami (LinkedIn, witryny chronione przez Cloudflare) wciąż może wywołać blokady; możesz skonfigurować opóźnienia wyodrębniania, by odpowiednio je spowolnić. Rozszerzenie nie rotuje serwerów proxy ani odcisków przeglądarki.
Jakie formaty eksportu są obsługiwane?
CSV, XLSX (zgodny z Excelem), JSON oraz bezpośrednie kopiowanie do schowka w celu wklejenia do Arkuszy Google, Excela lub dowolnego CRM-a. Eksporty zapisują się lokalnie w twoim folderze pobierania.
Czy moje wyodrębnione dane opuszczają przeglądarkę?
Nie. Wyodrębnione rekordy przechowywane są lokalnie w IndexedDB. Jedyne żądanie sieciowe następuje podczas automatycznego wykrywania, gdy struktura HTML strony (a nie jej treść) jest wysyłana do naszego API analitycznego w celu zaproponowania selektorów. Same twoje wyodrębnione dane nigdy nie są przesyłane.
Czy potrafi ominąć płatne ściany lub bramki logowania?
Nie. ScrapeMaster wyodrębnia dane ze stron, które już widzisz w swojej przeglądarce. Nie omija płatnych ścian, nie pokonuje wymogów logowania i nie rozwiązuje CAPTCHA. Jeśli widzisz to po zalogowaniu, ScrapeMaster potrafi to wyodrębnić.
Czy mogę zapisać swoje konfiguracje wyodrębniania i użyć ich ponownie później?
Tak. ScrapeMaster zapisuje twój układ kolumn, reguły paginacji i konfigurację podążania za szczegółami osobno dla każdej domeny. Przy późniejszej wizycie na tej samej stronie zapisana konfiguracja jest automatycznie stosowana ponownie.
W jakich przeglądarkach działa?
Chrome, Edge, Brave, Arc i każda przeglądarka oparta na Chromium. Rozszerzenie korzysta z API panelu bocznego Chrome, które nie jest dostępne w Firefoksie ani Safari.
Zainstaluj ScrapeMaster.
Darmowe na zawsze. Bez konta. Dwa kliknięcia. Odinstalujesz w kolejne dwa, jeśli się nie sprawdzi.
Dodaj do Chrome →